
Introduction
Construire un produit numérique réussi ne se limite pas à son lancement. Il s'agit de s'assurer qu'il peut croître avec votre entreprise. Beaucoup d'entreprises démarrent avec une excellente idée et une application fonctionnelle, pour ensuite la voir s'effondrer sous le poids du succès lorsque le nombre d'utilisateurs augmente ou que les fonctionnalités se multiplient.
De mauvaises décisions architecturales au départ peuvent coûter aux entreprises des milliers de dollars en réécritures et en opportunités manquées. Nous avons vu des entreprises montréalaises aux prises avec des applications qui fonctionnent parfaitement pour 100 utilisateurs mais qui plantent avec 1 000. La différence ? Une planification d'architecture évolutive dès le premier jour.
Cet article décompose les modèles d'architecture les plus efficaces qui aident les applications à croître en douceur. Que vous dirigiez une petite entreprise planifiant sa croissance ou que vous gériez un système d'entreprise, comprendre ces modèles vous aide à prendre des décisions éclairées concernant votre pile technologique.
Nous explorerons tout, des systèmes monolithiques traditionnels aux microservices modernes, en passant par les stratégies de mise à l'échelle des bases de données et les techniques de mise en cache. Chaque modèle a sa place, et savoir quand utiliser quelle approche peut faire économiser à votre entreprise beaucoup de temps et d'argent.
L'objectif n'est pas de vous convaincre qu'un modèle est universellement meilleur. Au lieu de cela, nous vous aiderons à comprendre les compromis afin que vous puissiez choisir ce qui correspond à vos besoins actuels et à vos objectifs futurs. Les décisions architecturales intelligentes équilibrent la fonctionnalité immédiate avec la flexibilité à long terme.
Comprendre les fondamentaux de l'architecture évolutive
L'architecture évolutive fait référence à la capacité d'un système à gérer une charge de travail accrue sans sacrifier les performances ou nécessiter des reconceptions complètes. Pensez-y comme à la construction d'un restaurant. Une conception évolutive vous permet d'ajouter plus de tables, d'embaucher plus de personnel et d'agrandir la cuisine sans démolir les murs chaque fois que vous grandissez.
Dans le développement d'applications modernes, l'évolutivité signifie que votre logiciel peut accueillir plus d'utilisateurs, traiter plus de données et offrir plus de fonctionnalités à mesure que votre entreprise se développe. Il ne s'agit pas seulement de gérer la croissance. Il s'agit de le faire de manière efficace et rentable.
Principes clés qui favorisent l'évolutivité
Plusieurs principes fondamentaux guident la conception de systèmes évolutifs. Le couplage faible garantit que les modifications apportées à une partie de votre système ne brisent pas les autres. Cette indépendance rend les mises à jour et la mise à l'échelle beaucoup plus simples.
L'absence d'état aide les systèmes à évoluer horizontalement en garantissant que n'importe quel serveur peut gérer n'importe quelle requête. Lorsque les serveurs n'ont pas besoin de se souvenir des interactions précédentes, vous pouvez les ajouter ou les supprimer librement en fonction de la demande.
La redondance protège contre les défaillances tout en permettant la distribution de la charge. Avoir plusieurs instances de composants critiques signifie que votre application reste en ligne même lorsque des parties individuelles échouent. Cette approche répartit également le trafic sur les ressources de manière plus efficace.
La modularité décompose les systèmes complexes en parties gérables. Chaque module gère des fonctionnalités spécifiques, ce qui facilite la mise à l'échelle uniquement des parties qui en ont besoin. Vous n'avez pas besoin de dupliquer toute votre application lorsqu'une seule fonctionnalité nécessite plus de ressources.
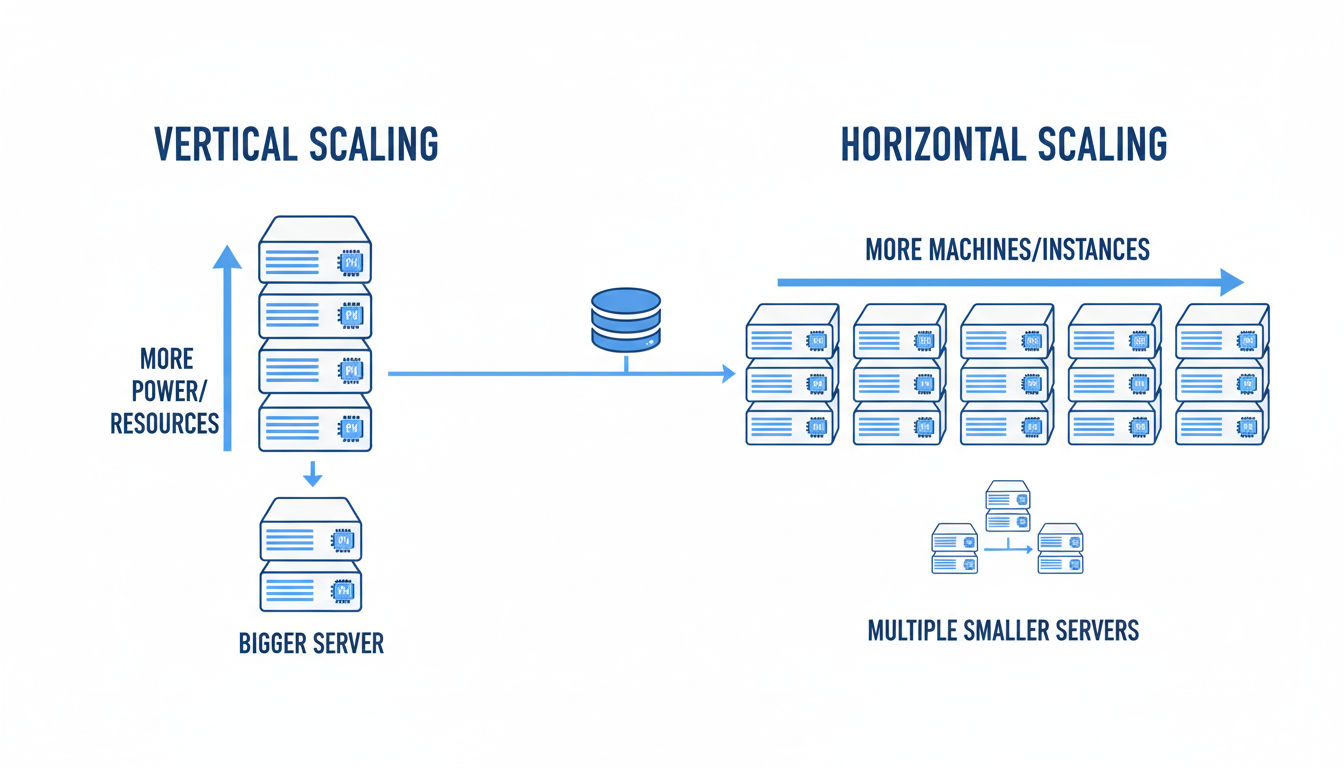
Approches de mise à l'échelle verticale et horizontale
La mise à l'échelle verticale signifie ajouter plus de puissance aux serveurs existants. Vous améliorez la RAM, ajoutez des processeurs plus rapides ou augmentez la capacité de stockage. C'est simple et ne nécessite pas de modifications de l'application. Cependant, elle a des limites physiques et peut créer des points de défaillance uniques.
La mise à l'échelle horizontale ajoute plus de serveurs pour distribuer la charge de travail. Au lieu d'une machine puissante, vous utilisez plusieurs machines plus petites travaillant ensemble. Cette approche offre un potentiel de croissance pratiquement illimité et une meilleure tolérance aux pannes.
La plupart des stratégies d'architecture évolutive modernes favorisent la mise à l'échelle horizontale. Les plateformes cloud facilitent le démarrage automatique de nouvelles instances en fonction de la demande. Vous ne payez que ce que vous utilisez et vous pouvez réduire l'échelle pendant les périodes calmes.
Les meilleurs systèmes combinent souvent les deux approches de manière stratégique. Certains composants bénéficient de la mise à l'échelle verticale tandis que d'autres évoluent horizontalement. Comprendre les goulots d'étranglement de votre application vous aide à choisir la bonne approche pour chaque composant.
Quand prioriser l'évolutivité de l'architecture
Toutes les applications n'ont pas besoin d'une évolutivité de niveau entreprise dès le premier jour. Un site web d'entreprise locale desservant quelques centaines de visiteurs par mois ne nécessite pas la même architecture qu'une plateforme attendant des millions d'utilisateurs.
Envisagez une architecture évolutive lorsque vous anticipez une croissance significative dans les 12 à 18 mois. Si votre modèle d'affaires dépend d'une acquisition rapide d'utilisateurs ou de pics de trafic saisonniers, planifier l'évolutivité dès le départ vous évite des réécritures coûteuses plus tard.
Les signes que vous devez vous concentrer sur l'évolutivité incluent des problèmes de performance fréquents pendant les heures de pointe, des difficultés à ajouter de nouvelles fonctionnalités sans impacts à l'échelle du système, ou des coûts d'infrastructure croissants qui ne correspondent pas aux taux de croissance. Ces symptômes suggèrent que votre architecture actuelle ne peut pas soutenir votre trajectoire.
Travailler avec des équipes de développement expérimentées vous aide à évaluer vos besoins réels par rapport à une sur-ingénierie. Chez Vohrtech, nous aidons les entreprises à dimensionner correctement leurs investissements architecturaux en fonction de projections de croissance réalistes et de contraintes budgétaires.
Modèle d'architecture monolithique
L'architecture monolithique regroupe tous les composants d'application dans une seule base de code unifiée. Votre interface utilisateur, votre logique métier et vos couches d'accès aux données vivent tous ensemble dans une unité déployable. C'est l'approche traditionnelle qui a alimenté la plupart des applications pendant des décennies.
Pensez-y comme à un seul bâtiment où chaque département opère sous un même toit. Tout se connecte directement, la communication est simple et vous déployez toute la structure en une seule pièce.
Structure et caractéristiques principales
Une application monolithique organise généralement le code en modules ou packages, mais ils se compilent et s'exécutent tous ensemble. Lorsque vous mettez à jour une partie de l'application, vous redéployez l'ensemble du système. Cette intégration étroite simplifie le développement aux premières étapes.
La base de code partage des ressources communes comme les bases de données, la mémoire et la puissance de traitement. Toutes les fonctionnalités accèdent directement aux mêmes structures de données sans appels réseau ni protocoles de communication complexes. Cet accès direct facilite la gestion des transactions et de la cohérence des données.
Les équipes de développement peuvent travailler sur une application monolithique en utilisant des outils et des pratiques familiers. Le débogage est simple puisque tout s'exécute dans le même processus. Vous pouvez tracer les chemins d'exécution directement sans sauter entre les services ou les systèmes.
Avantages pour les applications petites à moyennes
L'architecture monolithique brille lorsque vous démarrez ou exécutez des applications de complexité modérée. La vitesse de développement est généralement plus rapide puisque vous n'avez pas besoin de gérer plusieurs déploiements ou communications de services.
Les tests sont plus simples car vous testez une application au lieu de coordonner des tests sur plusieurs services. Vous pouvez exécuter l'application entière localement sur la machine d'un développeur, ce qui rend le débogage et l'itération rapides.
Le déploiement est simple. Vous construisez un package et le déployez sur vos serveurs. Il n'est pas nécessaire d'orchestrer plusieurs services ou de gérer des pipelines de déploiement complexes. Cette simplicité réduit considérablement les frais opérationnels.
Les performances peuvent en fait être meilleures pour les applications monolithiques à petite échelle. Les appels de fonction directs sont plus rapides que les requêtes réseau entre services. Vous évitez la latence et la complexité qu'introduisent les systèmes distribués.
Pour les entreprises à Montréal et ailleurs, l'architecture monolithique offre souvent le chemin le plus rapide vers le marché. Vous pouvez valider votre modèle d'affaires et recueillir les commentaires des utilisateurs sans investir dans une infrastructure complexe.
Limites et contraintes d'évolutivité
À mesure que les applications grandissent, l'architecture monolithique montre ses limites. La mise à l'échelle nécessite de dupliquer l'application entière, même si une seule fonctionnalité a besoin de plus de ressources. Cette approche gaspille les dépenses d'infrastructure.
Les grandes bases de code deviennent difficiles à maintenir. Les modifications dans un domaine peuvent affecter de manière inattendue les autres. Le couplage étroit qui simplifiait le développement initial crée maintenant des goulots d'étranglement à mesure que les équipes grandissent.
Le déploiement devient plus risqué avec la taille. Chaque modification nécessite de redéployer tout, augmentant les chances de défaillances à l'échelle du système. Annuler les problèmes signifie revenir à l'application entière.
Les choix technologiques deviennent figés. Vous ne pouvez pas facilement utiliser différents langages de programmation ou frameworks pour différentes fonctionnalités. L'application entière doit utiliser des technologies compatibles, limitant vos options à mesure que les exigences évoluent.
Meilleurs cas d'utilisation
L'architecture monolithique fonctionne bien pour les applications avec des modèles de trafic prévisibles et modérés. Si vous construisez un outil d'entreprise interne, un système de gestion de contenu ou un site de commerce électronique simple, la conception monolithique suffit souvent.
Les startups validant l'adéquation produit-marché bénéficient de la simplicité monolithique. Vous pouvez itérer rapidement sans les frais généraux de gestion de systèmes distribués. Une fois que vous avez prouvé votre concept et compris vos besoins de mise à l'échelle, vous pouvez faire évoluer l'architecture.
Les applications avec de fortes exigences de cohérence favorisent également la conception monolithique. Lorsque chaque opération doit voir les mêmes données immédiatement, garder tout dans un système simplifie la gestion des transactions.
Les petites et moyennes entreprises avec des équipes techniques limitées trouvent les applications monolithiques plus faciles à maintenir. Vous n'avez pas besoin d'expertise DevOps spécialisée ou de systèmes de surveillance complexes pour maintenir les choses en bon état de marche.
Modèle d'architecture de microservices
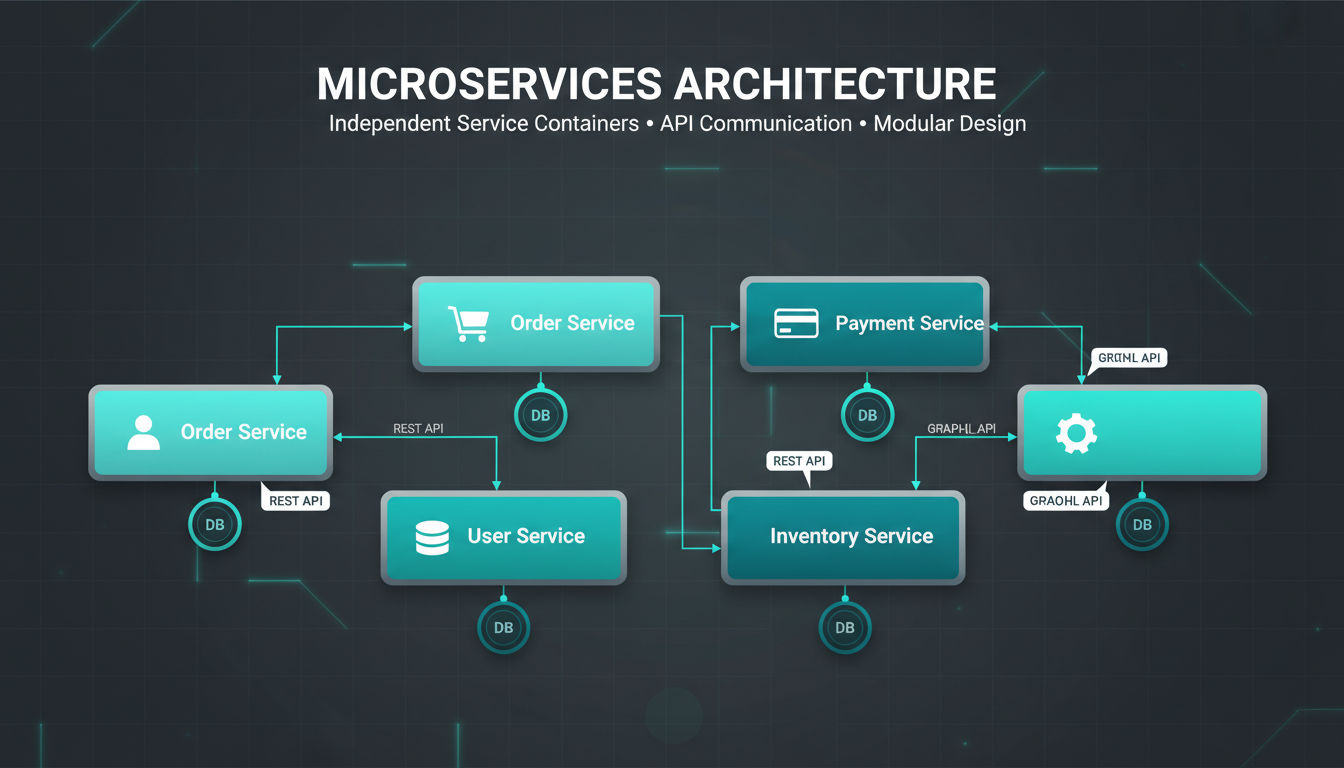
L'architecture de microservices décompose les applications en petits services indépendants qui gèrent chacun des fonctions métier spécifiques. Au lieu d'une grande application, vous construisez de nombreux services ciblés qui travaillent ensemble via des interfaces bien définies.
Chaque service possède ses données, s'exécute indépendamment et peut être développé, déployé et mis à l'échelle séparément. Cette séparation crée une flexibilité que les systèmes monolithiques ne peuvent égaler.
Décomposition en services indépendants
La clé des microservices est d'identifier des limites claires entre les capacités métier. Une application de commerce électronique typique pourrait séparer les services pour les comptes utilisateurs, les catalogues de produits, les paniers d'achat, les paiements et l'exécution des commandes.
Chaque service maintient sa propre base de données et sa logique métier. Le service utilisateur n'accède pas directement à la base de données des commandes. Au lieu de cela, les services communiquent via des API ou des systèmes de messagerie. Cette indépendance signifie que les équipes peuvent travailler sur différents services simultanément sans frais généraux de coordination.
Les services doivent être suffisamment petits pour qu'une seule équipe puisse les comprendre et les maintenir complètement. Si un service devient trop complexe, il est souvent divisé en services plus petits. Cette approche garde les bases de code gérables et réduit le risque de modifications.
L'indépendance s'étend aux choix technologiques. Un service pourrait utiliser Python et PostgreSQL tandis qu'un autre utilise Node.js et MongoDB. Les équipes choisissent les meilleurs outils pour les exigences spécifiques de chaque service plutôt que de faire des compromis sur une pile universelle.
Avantages pour l'architecture évolutive
Les microservices excellent dans la mise à l'échelle car vous pouvez mettre à l'échelle des services individuels en fonction de leurs demandes spécifiques. Si votre service de recherche de produits reçoit 10 fois plus de trafic que votre service de paiement, vous déployez plus d'instances de recherche sans toucher au paiement.
Question rapide
Envie de transformer ça en vrai plan?
Si vous voulez de l’aide d’experts en stratégie, design, développement, marketing ou automatisation — on vous recommande le chemin le plus rapide vers vos objectifs.
Cette mise à l'échelle ciblée réduit considérablement les coûts d'infrastructure. Vous ne payez pas pour exécuter plusieurs copies de fonctionnalités qui n'ont pas besoin de capacité. Les plateformes cloud rendent cela encore plus efficace avec une mise à l'échelle automatique qui ajuste les ressources en fonction de la demande en temps réel.
L'isolation des pannes est un autre avantage majeur. Lorsqu'un service échoue, les autres continuent de fonctionner. Votre service de paiement pourrait rencontrer des problèmes, mais les utilisateurs peuvent toujours parcourir les produits et ajouter des articles à leurs paniers. Cette résilience maintient votre entreprise en marche même pendant des pannes partielles.
La vélocité de développement augmente à mesure que les équipes travaillent indépendamment. Différents services peuvent publier des mises à jour selon des calendriers différents. Votre équipe marketing peut lancer de nouvelles fonctionnalités sans attendre que l'équipe infrastructure termine son travail.
L'évolution technologique devient plus facile. Vous pouvez adopter progressivement de nouveaux frameworks ou langages en construisant de nouveaux services avec des outils modernes tout en maintenant les services existants. Cette approche incrémentale réduit les risques par rapport aux réécritures complètes.
Modèles de communication entre services
Les services ont besoin de moyens fiables pour communiquer. La communication synchrone utilise des API REST HTTP ou gRPC. Un service fait une requête et attend une réponse. Ce modèle fonctionne bien pour les opérations qui nécessitent des résultats immédiats, comme la récupération de données de profil utilisateur.
La communication asynchrone utilise des files d'attente de messages ou des flux d'événements. Les services publient des événements vers un courtier, et d'autres services les consomment lorsqu'ils sont prêts. Ce modèle gère mieux les opérations à volume élevé et fournit un tampon naturel pendant les pics de trafic.
Les mécanismes de découverte de services aident les services à se trouver dans des environnements dynamiques. À mesure que les instances augmentent et diminuent, les systèmes de découverte maintiennent les informations de routage actuelles. Cette automatisation est essentielle pour gérer des dizaines ou des centaines d'instances de service.
Les passerelles API fournissent un point d'entrée unique pour les applications clientes. Elles gèrent l'authentification, la limitation de débit et le routage des requêtes vers les services appropriés. Cette couche protège les clients de la complexité de l'architecture de microservices sous-jacente.
Quand adopter pour votre entreprise
Les microservices ont du sens lorsque votre application a des domaines fonctionnels distincts avec des besoins de mise à l'échelle différents. Si certaines fonctionnalités nécessitent constamment plus de ressources que d'autres, la mise à l'échelle indépendante offre des avantages clairs.
Les organisations avec plusieurs équipes de développement bénéficient de l'indépendance des microservices. Chaque équipe peut posséder des services spécifiques, réduisant les frais généraux de coordination et permettant le développement parallèle. Cette structure fonctionne particulièrement bien pour les entreprises connaissant une croissance rapide.
Envisagez les microservices lorsque vous avez besoin de flexibilité technologique. Si différentes parties de votre application ont des exigences très différentes, la capacité de choisir des outils spécialisés pour chaque service offre des avantages significatifs.
Cependant, les microservices introduisent une complexité opérationnelle. Vous avez besoin d'une surveillance, d'une journalisation et d'une automatisation de déploiement robustes. Les petites équipes ou les entreprises en phase de démarrage trouvent souvent que ces frais généraux l'emportent sur les avantages jusqu'à ce qu'elles atteignent une certaine échelle.
Chez Vohrtech, nous aidons les entreprises à évaluer si les microservices correspondent à leur stade actuel et à leurs plans futurs. Parfois, un monolithe bien conçu vous sert mieux initialement, avec un chemin de migration clair vers les microservices à mesure que vous grandissez.
Modèle d'architecture en couches (N-tiers)
L'architecture en couches organise les applications en couches horizontales, chacune avec des responsabilités spécifiques. Cette séparation des préoccupations crée des limites claires qui rendent les applications plus faciles à comprendre, à maintenir et à mettre à l'échelle.
L'implémentation la plus courante utilise trois ou quatre niveaux. Chaque couche ne communique qu'avec les couches adjacentes, créant un flux structuré de données et de logique à travers votre système.
Séparation des préoccupations dans la conception du système
Le principe fondamental derrière l'architecture en couches est que chaque couche gère un type de responsabilité. Cette spécialisation rend le code plus maintenable car les modifications apportées à une couche affectent rarement les autres.
Lorsque vous devez changer la façon dont les données sont stockées, vous modifiez la couche de données sans toucher au code de présentation. Si vous repensez votre interface utilisateur, la logique métier reste inchangée. Cette indépendance accélère le développement et réduit les bugs.
Les limites claires des couches facilitent également l'application des politiques de sécurité. Vous pouvez vous assurer que seule la couche de données accède directement aux bases de données, empêchant l'accès non autorisé depuis les couches supérieures. Cette structure prend naturellement en charge les meilleures pratiques de sécurité.
Les tests deviennent plus systématiques avec l'architecture en couches. Vous pouvez tester chaque couche indépendamment, en simulant les couches au-dessus et en dessous. Cette isolation rend les tests unitaires plus efficaces et les tests d'intégration plus ciblés.
Couches de présentation, de logique métier et de données
La couche de présentation gère toute interaction utilisateur. Elle affiche les informations et capture les entrées utilisateur. Cette couche contient vos pages web, écrans d'applications mobiles ou points de terminaison API. Elle devrait contenir une logique minimale, se concentrant uniquement sur l'expérience utilisateur.
La couche de logique métier traite le travail réel que votre application effectue. Elle applique les règles métier, effectue des calculs et coordonne les flux de travail. Cette couche est indépendante de la technologie, ce qui signifie qu'elle ne se soucie pas de savoir si les requêtes proviennent d'un navigateur web ou d'une application mobile.
La couche de données gère toute la persistance et la récupération des données. Elle gère les connexions aux bases de données, exécute les requêtes et mappe les enregistrements de base de données aux objets d'application. Cette couche protège le reste de votre application des détails spécifiques à la base de données.
Beaucoup d'applications ajoutent une quatrième couche de service entre la présentation et la logique métier. Cette couche fournit une API propre pour les consommateurs externes et gère les préoccupations transversales comme l'authentification, la journalisation et la mise en cache.
Avantages et compromis en matière d'évolutivité
L'architecture en couches prend en charge les stratégies de mise à l'échelle verticale et horizontale. Vous pouvez mettre à l'échelle des couches spécifiques indépendamment en fonction de leurs besoins en ressources. La couche de présentation pourrait avoir besoin de plus d'instances pour gérer le trafic utilisateur tandis que la couche de données reste stable.
Les stratégies de mise en cache fonctionnent naturellement avec l'architecture en couches. Vous pouvez mettre en cache au niveau de la couche de présentation pour réduire les requêtes serveur, au niveau de la couche métier pour éviter les calculs répétés, ou au niveau de la couche de données pour minimiser les requêtes de base de données.
L'équilibrage de charge s'intègre proprement dans les conceptions en couches. Vous pouvez distribuer les requêtes sur plusieurs instances de couche de présentation pendant qu'elles se connectent toutes à la même couche de logique métier. Cette séparation rend la mise à l'échelle plus prévisible.
Cependant, l'architecture en couches peut introduire des frais généraux de performance. Chaque couche ajoute une certaine latence à mesure que les requêtes passent. Pour les applications nécessitant une latence extrêmement faible, ces frais généraux peuvent être problématiques.
La structure rigide peut parfois sembler contraignante. Lorsque les fonctionnalités couvrent naturellement plusieurs couches, vous pourriez vous retrouver à transmettre des données à travers des couches qui ajoutent peu de valeur. Trouver le bon équilibre entre structure et pragmatisme nécessite de l'expérience.
Considérations de mise en œuvre
Commencez par définir clairement ce qui appartient à chaque couche. Documentez ces limites et appliquez-les par le biais de revues de code et de directives architecturales. La cohérence compte plus que la perfection dans le placement exact de chaque composant.
Utilisez l'injection de dépendances pour gérer les connexions entre les couches. Cette approche rend les couches plus testables et flexibles. Vous pouvez échanger des implémentations sans changer les couches qui en dépendent.
Envisagez d'utiliser des projets ou des modules séparés pour chaque couche dans votre base de code. Cette séparation physique renforce les limites logiques et rend plus difficile pour les développeurs de créer accidentellement des dépendances inappropriées.
Surveillez les performances à travers les couches pour identifier les goulots d'étranglement. Si la couche de données devient une contrainte, vous pouvez optimiser les requêtes ou ajouter de la mise en cache sans réécrire votre logique métier ou votre code de présentation.
Pour les entreprises évaluant leurs options d'architecture, la conception en couches offre un terrain d'entente entre la simplicité monolithique et la complexité des microservices. Elle fournit structure et évolutivité tout en restant gérable pour les petites équipes.
Modèle d'architecture événementielle
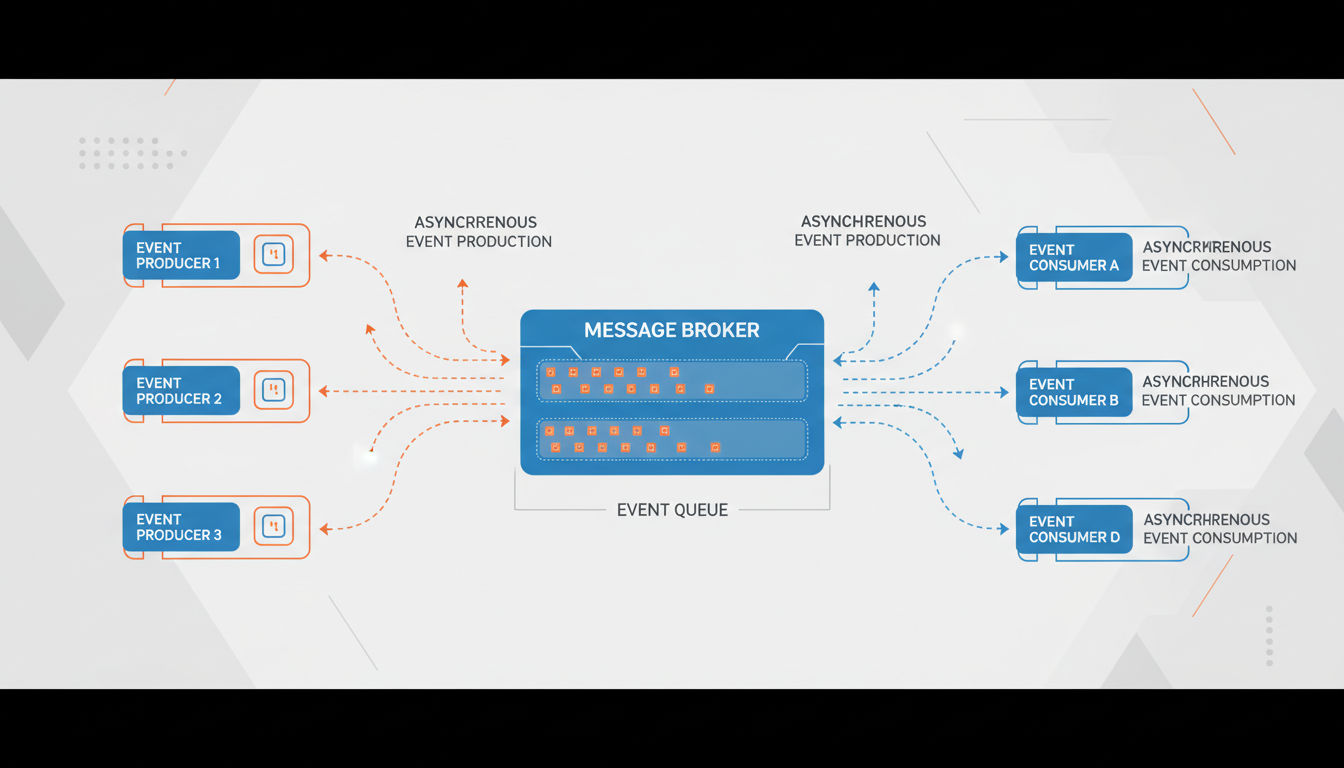
L'architecture événementielle organise les systèmes autour de la production, de la détection et de la réaction aux événements. Au lieu que les composants s'appellent directement, ils communiquent en publiant et en s'abonnant à des événements qui représentent des changements d'état significatifs.
Un événement pourrait être « utilisateur enregistré », « commande passée » ou « paiement traité ». Les composants intéressés par ces événements réagissent indépendamment sans savoir qui a généré l'événement.
Communication asynchrone pour l'architecture évolutive
Les systèmes événementiels excellent dans la gestion d'opérations qui n'ont pas besoin de réponses immédiates. Lorsqu'un utilisateur passe une commande, vous pouvez immédiatement confirmer la réception pendant que le traitement du paiement, la mise à jour de l'inventaire et l'envoi de notifications se font de manière asynchrone en arrière-plan.
Cette approche asynchrone évite les goulots d'étranglement. Si votre service de messagerie est lent, cela ne retarde pas la confirmation de commande. Chaque composant traite les événements à son propre rythme, et les ralentissements temporaires dans un domaine ne se propagent pas à travers tout le système.
Le découplage est l'avantage majeur ici. Les producteurs d'événements ne savent pas et ne se soucient pas de qui consomme leurs événements. Vous pouvez ajouter de nouvelles fonctionnalités en vous abonnant aux événements existants sans modifier les systèmes qui les génèrent. Cette flexibilité accélère considérablement le développement.
La mise en tampon se produit naturellement dans les systèmes événementiels. Lorsque le trafic augmente, les événements s'accumulent et sont traités à mesure que les ressources deviennent disponibles. Cette résilience intégrée aide les systèmes à gérer des modèles de charge imprévisibles sans planter.
Producteurs, consommateurs et courtiers d'événements
Les producteurs d'événements génèrent des événements lorsque des actions importantes se produisent. Il peut s'agir d'actions utilisateur, de processus système ou d'intégrations externes. Les producteurs publient des événements vers un courtier sans savoir qui les consommera.
Les courtiers d'événements agissent comme intermédiaires qui reçoivent, stockent et acheminent les événements. Les courtiers populaires incluent Apache Kafka, RabbitMQ et les services cloud comme AWS SNS/SQS. Ils garantissent que les événements ne sont pas perdus et peuvent être rejoués si nécessaire.
Les consommateurs d'événements s'abonnent à des types d'événements spécifiques qui les intéressent. Plusieurs consommateurs peuvent réagir au même événement différemment. Lorsqu'une commande est passée, un consommateur pourrait envoyer un email de confirmation, un autre met à jour l'inventaire, et un troisième déclenche l'exécution.
Cette relation plusieurs-à-plusieurs crée une flexibilité puissante. Ajouter de nouvelles fonctionnalités signifie souvent simplement ajouter un nouveau consommateur. Vous ne modifiez pas le code existant, réduisant le risque de casser les fonctionnalités qui fonctionnent.
Les schémas d'événements définissent la structure des événements. Les schémas bien conçus incluent toutes les informations dont les consommateurs ont besoin pour réagir de manière appropriée. Ils doivent être versionnés pour gérer l'évolution à mesure que votre système grandit.
Capacités de traitement en temps réel
L'architecture événementielle permet un véritable traitement en temps réel. Les systèmes peuvent réagir aux événements en quelques millisecondes après leur occurrence. Cette capacité alimente des fonctionnalités comme les tableaux de bord en direct, les notifications instantanées et les analyses en temps réel.
Les frameworks de traitement de flux comme Apache Flink ou Kafka Streams vous permettent d'analyser les événements au fur et à mesure qu'ils circulent dans votre système. Vous pouvez détecter des modèles, calculer des agrégats et déclencher des actions basées sur des séquences d'événements en temps réel.
Cette capacité en temps réel crée des avantages concurrentiels. Les sites de commerce électronique peuvent ajuster les prix en fonction de la demande instantanément. Les systèmes de surveillance peuvent alerter les équipes des problèmes avant que les utilisateurs ne les remarquent. Les outils de service client peuvent fournir aux agents des informations à la seconde près.
Le traitement d'événements complexes identifie des modèles significatifs à partir de plusieurs événements simples. Vous pourriez déclencher une alerte de fraude non pas à partir d'une seule transaction, mais à partir d'un modèle de transactions se produisant dans une séquence ou un timing inhabituel.
Applications commerciales et avantages
L'architecture événementielle s'adapte naturellement aux processus métier modernes. De nombreux flux de travail du monde réel sont intrinsèquement basés sur des événements. Le parcours d'un client à travers votre entreprise génère des événements à chaque point de contact, de la visite initiale à l'achat jusqu'aux interactions de support.
Les pistes d'audit et la conformité deviennent plus simples avec les systèmes événementiels. Chaque action importante génère un enregistrement d'événement immuable. Vous pouvez reconstruire l'état du système à tout moment en rejouant les événements, ce qui est inestimable pour le débogage et la conformité réglementaire.
L'intégration avec les systèmes externes devient plus propre. Au lieu d'un couplage étroit avec les API partenaires, vous générez des événements que les services d'intégration consomment. Si l'API d'un partenaire change, vous mettez à jour uniquement le service d'intégration, pas votre logique métier principale.
L'évolutivité s'améliore considérablement car les consommateurs d'événements peuvent évoluer indépendamment. Si l'envoi d'emails devient un goulot d'étranglement, vous ajoutez plus d'instances de consommateur d'email sans toucher au traitement des commandes ou à la gestion de l'inventaire.
Pour les entreprises montréalaises et au-delà, l'architecture événementielle bénéficie particulièrement aux applications avec des flux de travail complexes, plusieurs intégrations ou des exigences de réactivité en temps réel. Le modèle nécessite une infrastructure et une surveillance plus sophistiquées, mais la flexibilité et l'évolutivité justifient souvent l'investissement à mesure que les entreprises grandissent.
Modèles de mise à l'échelle de base de données
Les performances de la base de données deviennent souvent le premier goulot d'étranglement majeur à mesure que les applications évoluent. Alors que les serveurs d'application peuvent évoluer horizontalement facilement, les bases de données nécessitent des stratégies plus sophistiquées pour gérer l'augmentation des volumes de données et des charges de requêtes.
La bonne approche de mise à l'échelle de base de données dépend de vos caractéristiques de données, de vos exigences de cohérence et de vos modèles de requêtes. La plupart des systèmes réussis combinent plusieurs stratégies.
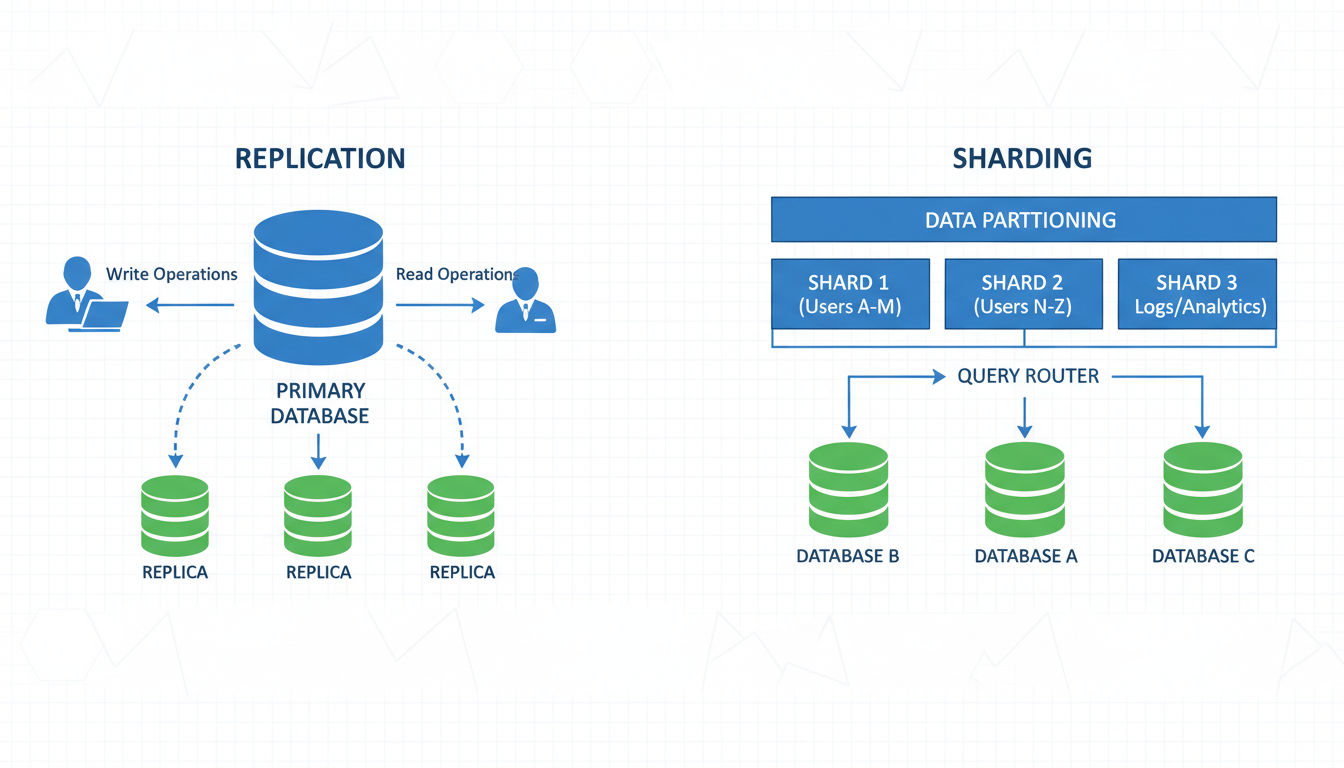
Stratégies de réplication de base de données
La réplication crée plusieurs copies de votre base de données sur différents serveurs. La copie principale gère les écritures tandis que les répliques gèrent les requêtes de lecture. Cette distribution augmente considérablement la capacité de lecture, qui est souvent le premier besoin de mise à l'échelle.
La réplication maître-esclave utilise une base de données principale qui accepte toutes les écritures. Les modifications se répliquent vers plusieurs esclaves en lecture seule qui gèrent le trafic de requêtes. Cette configuration fonctionne bien lorsque votre application effectue beaucoup plus de lectures que d'écritures, ce qui décrit la plupart des applications commerciales.
La réplication multi-maître permet des écritures vers plusieurs instances de base de données simultanément. Cette approche offre une meilleure évolutivité d'écriture et une distribution géographique mais introduit de la complexité autour de la résolution des conflits. Lorsque deux maîtres reçoivent des mises à jour conflictuelles, votre système a besoin de règles claires pour la résolution.
Le retard de réplication est une considération clé. Les modifications apportées à la base de données principale prennent du temps à se propager aux répliques. Les applications doivent gérer les scénarios où elles lisent des données légèrement obsolètes. Pour de nombreux cas d'utilisation, cette cohérence éventuelle est acceptable.
La réplication géographique place des répliques de base de données dans différentes régions. Les utilisateurs se connectent à la réplique la plus proche, réduisant considérablement la latence. Cette stratégie améliore à la fois les performances et les capacités de reprise après sinistre.
Partitionnement et fragmentation dans l'architecture d'application
Le partitionnement divise votre base de données horizontalement, distribuant les lignes sur plusieurs instances de base de données. Chaque fragment contient un sous-ensemble de vos données totales. Cette approche met à l'échelle à la fois les lectures et les écritures puisque différents fragments gèrent différentes portions de votre charge de travail.
La clé de partitionnement détermine comment les données sont distribuées. Les stratégies courantes incluent le partitionnement par ID utilisateur, région géographique ou plages de dates. Choisir la bonne clé est critique car elle affecte à la fois les performances et la complexité.
Les clés de partitionnement efficaces distribuent les données uniformément sur les fragments et s'alignent avec vos modèles de requêtes. Si la plupart des requêtes filtrent par ID client, le partitionnement par client a du sens. Les requêtes pour un seul client touchent un fragment, évitant les opérations coûteuses inter-fragments.
Les requêtes inter-fragments deviennent difficiles avec le partitionnement. Les opérations qui nécessitent des données de plusieurs fragments nécessitent une coordination au niveau de l'application. Cette complexité est pourquoi le partitionnement est généralement un dernier recours après avoir épuisé les autres options.
Le partitionnement vertical divise les tables par colonnes plutôt que par lignes. Les colonnes fréquemment consultées vont dans une partition tandis que les colonnes rarement utilisées vont dans une autre. Cette stratégie réduit les E/S pour les requêtes courantes et peut améliorer l'efficacité du cache.
CQRS (Ségrégation de responsabilité de commande et de requête)
CQRS sépare les opérations de lecture et d'écriture en différents modèles. Les opérations d'écriture vont vers un modèle de commande optimisé pour l'intégrité et la cohérence des données. Les opérations de lecture utilisent des modèles de requête optimisés pour des modèles d'accès spécifiques.
Cette séparation vous permet de mettre à l'échelle les lectures et les écritures indépendamment. Vous pourriez avoir une base de données d'écriture avec de fortes garanties de cohérence et plusieurs bases de données de lecture avec des données dénormalisées optimisées pour différents modèles de requêtes.
Le modèle d'écriture maintient des données normalisées avec des règles métier strictes. Lorsque les données changent, les événements mettent à jour un ou plusieurs modèles de lecture de manière asynchrone. Chaque modèle de lecture structure les données parfaitement pour ses requêtes spécifiques.
CQRS bénéficie particulièrement aux applications avec des domaines complexes où les modèles de lecture et d'écriture diffèrent considérablement. Les rapports et les analyses ont souvent besoin de structures de données différentes des opérations transactionnelles. CQRS vous permet d'optimiser les deux sans compromis.
Le modèle introduit de la complexité. Vous maintenez plusieurs modèles de données et gérez la cohérence éventuelle entre eux. Pour les applications plus simples, les approches traditionnelles suffisent souvent. CQRS brille lorsque la complexité des requêtes ou l'échelle exige une optimisation spécialisée.
Choisir la bonne approche
Commencez par l'approche la plus simple qui répond à vos besoins. La plupart des applications devraient commencer par la réplication, en ajoutant des répliques de lecture à mesure que la charge de requêtes augmente. Cette stratégie est bien comprise, largement prise en charge et relativement simple à mettre en œuvre.
Envisagez le partitionnement uniquement lorsque vous avez épuisé les options de mise à l'échelle verticale et de réplication. Le partitionnement introduit une complexité significative à la fois dans le code d'application et les opérations. Assurez-vous que les avantages justifient les coûts.
Évaluez attentivement vos exigences de cohérence. Si votre application peut tolérer la cohérence éventuelle, vous gagnez plus d'options de mise à l'échelle. Les exigences de cohérence forte limitent vos choix et réduisent généralement l'échelle maximale.
Surveillez continuellement vos métriques de performance de base de données. La latence des requêtes, l'utilisation du pool de connexions et le retard de réplication vous indiquent quand vous approchez des limites. La mise à l'échelle proactive évite les urgences de performance.
Travailler avec des équipes expérimentées vous aide à éviter les pièges courants. Chez Vohrtech, nous avons aidé des entreprises à mettre en œuvre des stratégies de mise à l'échelle de base de données appropriées à leur stade de croissance, évitant à la fois la sous-ingénierie et l'optimisation prématurée.
Stratégies de mise en cache pour l'évolutivité
La mise en cache stocke les données fréquemment consultées dans des emplacements à accès rapide, réduisant considérablement la charge sur les systèmes backend. Une mise en cache efficace peut améliorer les temps de réponse de plusieurs ordres de grandeur tout en réduisant les coûts d'infrastructure.
La clé est de mettre en cache aux bonnes couches avec des stratégies d'invalidation appropriées. Une mauvaise mise en cache crée des problèmes de données obsolètes tandis qu'une bonne mise en cache apparaît invisible pour les utilisateurs.
Réseaux de diffusion de contenu (CDN)
Les CDN mettent en cache les ressources statiques comme les images, CSS, JavaScript et vidéos dans des emplacements périphériques du monde entier. Lorsque les utilisateurs demandent ces fichiers, ils sont servis depuis des serveurs CDN à proximité plutôt que depuis vos serveurs d'origine.
Cette distribution géographique réduit considérablement la latence. Un utilisateur à Montréal charge votre site depuis un emplacement périphérique canadien tandis qu'un utilisateur à Tokyo charge depuis un emplacement périphérique asiatique. Les deux obtiennent des performances rapides sans que vous gériez des serveurs mondialement.
Les CDN réduisent également les coûts de bande passante et la charge des serveurs d'origine. Vos serveurs n'ont besoin de servir du contenu qu'au CDN, pas à chaque utilisateur final. Cette réduction peut être substantielle pour les applications riches en médias.
Les CDN modernes offrent plus que la mise en cache de fichiers statiques. Ils peuvent mettre en cache les réponses API, gérer la terminaison SSL, fournir une protection DDoS, et même exécuter du code à la périphérie. Ces capacités font des CDN une infrastructure essentielle pour les applications web évolutives.
La configuration compte beaucoup. Définissez des en-têtes de cache appropriés pour contrôler ce qui est mis en cache et pour combien de temps. Les ressources statiques peuvent souvent être mises en cache pendant des jours ou des semaines, tandis que le contenu dynamique pourrait être mis en cache pendant des secondes ou des minutes.
Mise en cache au niveau de l'application
La mise en cache d'application stocke les résultats calculés, les pages rendues ou les données fréquemment consultées en mémoire. Cette approche évite les recalculs coûteux et les requêtes de base de données pour les requêtes répétées.
Les caches en mémoire comme Redis ou Memcached fournissent des temps d'accès en microsecondes. Ils sont parfaits pour les données de session, les préférences utilisateur et les valeurs calculées qui ne changent pas fréquemment.
La mise en cache de pages stocke des pages entières rendues. Lorsque la même page est demandée à nouveau, vous servez la version en cache au lieu de la régénérer. Cette stratégie fonctionne bien pour le contenu identique pour tous les utilisateurs ou qui change peu fréquemment.
La mise en cache de fragments stocke des portions de pages. Vous pourriez mettre en cache une barre latérale complexe ou des recommandations de produits tout en générant d'autres parties dynamiquement. Cette approche granulaire équilibre fraîcheur et performance.
L'invalidation du cache est la partie la plus difficile. Vous avez besoin de stratégies pour supprimer ou mettre à jour les données en cache lorsque les informations sous-jacentes changent. L'expiration basée sur le temps fonctionne pour certains cas d'utilisation, mais l'invalidation basée sur les événements fournit une meilleure cohérence.
Prochaine étape
Prêt pour un devis et un échéancier?
Envoyez un court message avec ce que vous construisez, votre deadline et à quoi ressemble le succès — on vous répond avec des prochaines étapes claires.
Mise en cache des requêtes de base de données
La mise en cache de requêtes stocke les résultats de base de données afin que les requêtes répétées renvoient des données en cache au lieu de toucher la base de données. Cette approche réduit la charge de la base de données et améliore les temps de réponse pour les requêtes courantes.
Les caches de requêtes au niveau de la base de données sont intégrés dans de nombreux systèmes de bases de données. Ils mettent automatiquement en cache les résultats de requêtes et les invalident lorsque les tables sous-jacentes changent. Cette gestion automatique simplifie la mise en œuvre mais offre moins de contrôle.
La mise en cache de requêtes au niveau de l'application vous donne plus de contrôle sur ce qui est mis en cache et pour combien de temps. Vous pouvez mettre en cache des agrégations complexes ou des rapports coûteux à générer mais qui n'ont pas besoin de précision en temps réel.
La mise en cache d'objets stocke des objets ou entités entiers plutôt que des résultats de requêtes bruts. Après avoir chargé un profil utilisateur depuis la base de données, vous mettez en cache l'objet utilisateur entier. Les requêtes ultérieures pour cet utilisateur sautent complètement la base de données.
La mise en cache d'instructions préparées améliore les performances en réutilisant les plans d'exécution de requêtes. Bien qu'elle ne mette pas en cache les résultats, cette approche réduit les frais généraux d'analyse et de planification des requêtes de manière répétée.
Impact sur les performances et l'architecture logicielle
Une mise en cache efficace peut réduire la charge backend de 80 à 90 % pour les applications à forte lecture. Cette réduction signifie que vous pouvez servir plus d'utilisateurs avec la même infrastructure ou réduire considérablement les coûts d'hébergement.
Les temps de réponse s'améliorent considérablement lorsque les données proviennent du cache au lieu des bases de données ou des API externes. Les utilisateurs bénéficient de chargements de pages plus rapides et d'applications plus réactives, améliorant la satisfaction et les taux de conversion.
La mise en cache fournit une protection naturelle contre les pics de trafic. Lorsqu'un contenu devient viral, les réponses en cache gèrent la vague sans submerger vos systèmes backend. Cette résilience évite les pannes pendant vos plus grandes opportunités.
Cependant, la mise en cache introduit de la complexité autour de la cohérence des données. Vous avez besoin de stratégies claires pour savoir quand les données en cache sont acceptables et quand vous avez besoin de précision en temps réel. La plupart des applications utilisent une approche hybride, mettant en cache agressivement là où c'est possible tout en gardant les chemins critiques frais.
Les stratégies de préchauffage du cache pré-remplissent les caches avant qu'ils ne soient nécessaires. Cette approche proactive évite les ruées vers le cache où de nombreuses requêtes découvrent simultanément des caches vides et submergent les systèmes backend en essayant de les remplir.
Modèles d'équilibrage de charge et de distribution
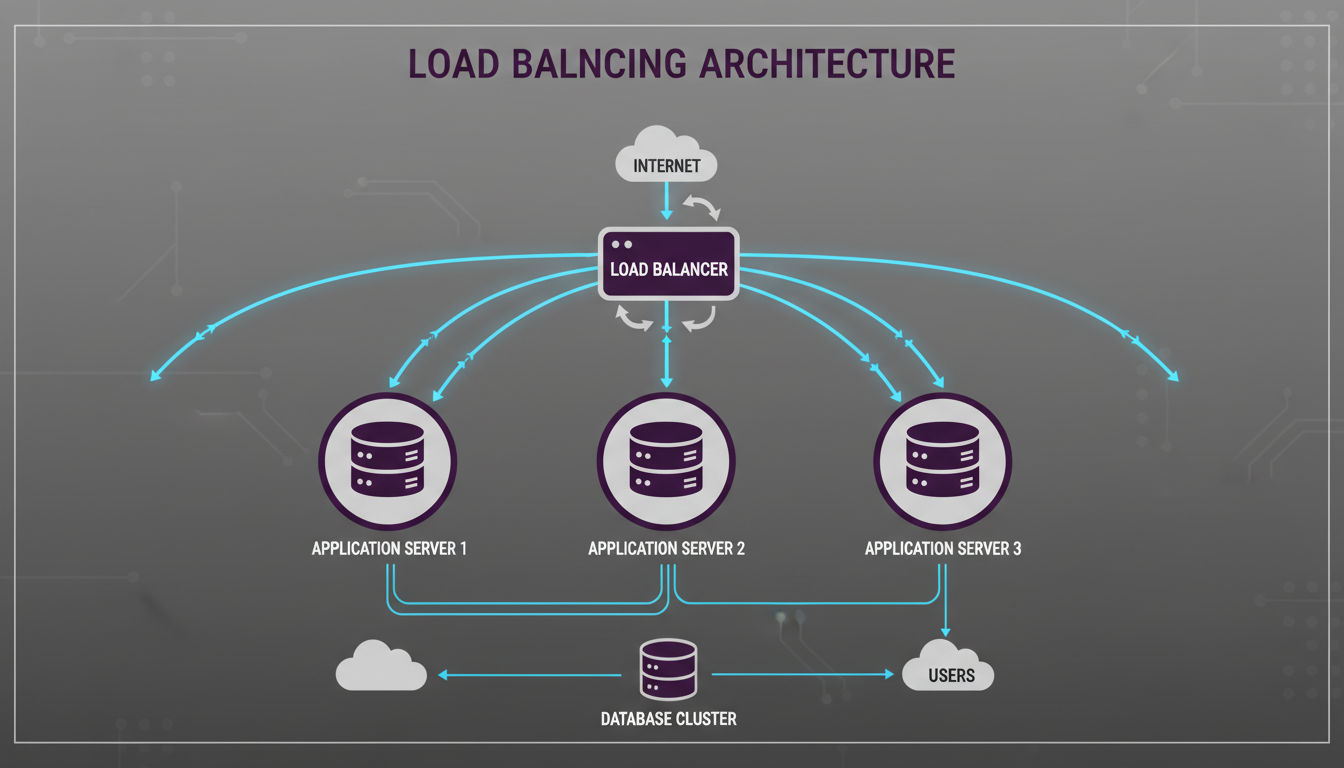
L'équilibrage de charge distribue le trafic entrant sur plusieurs serveurs, garantissant qu'aucun serveur unique ne soit submergé. Cette distribution améliore à la fois les performances et la fiabilité en répartissant la charge de travail et en fournissant de la redondance.
Les applications modernes utilisent l'équilibrage de charge à plusieurs couches, du DNS aux serveurs d'application en passant par les connexions de base de données.
Distribution du trafic sur plusieurs serveurs
Les équilibreurs de charge se situent entre les clients et vos serveurs d'application, routant chaque requête vers un serveur disponible. Ce rôle d'intermédiaire rend la mise à l'échelle transparente pour les utilisateurs. Vous pouvez ajouter ou supprimer des serveurs sans que les clients ne le remarquent.
Les équilibreurs de charge matériels sont des dispositifs physiques optimisés pour la distribution de trafic à haut débit. Ils offrent d'excellentes performances mais viennent avec des coûts importants et une flexibilité limitée.
Les équilibreurs de charge logiciels comme Nginx, HAProxy ou les solutions cloud natives offrent plus de flexibilité à moindre coût. Ils fonctionnent sur des serveurs standards et peuvent être configurés et mis à l'échelle de manière programmatique.
L'équilibrage de charge de couche 4 fonctionne au niveau de la couche transport, distribuant le trafic en fonction des adresses IP et des ports TCP/UDP. Il est rapide et efficace mais ne peut pas prendre de décisions basées sur des informations au niveau de l'application.
L'équilibrage de charge de couche 7 fonctionne au niveau de la couche application, examinant les en-têtes HTTP et le contenu. Cette inspection plus approfondie permet un routage sophistiqué basé sur les URL, les cookies ou les en-têtes personnalisés.
Algorithmes d'équilibrage de charge
Le round-robin distribue les requêtes séquentiellement sur les serveurs. Chaque serveur reçoit des requêtes à tour de rôle, fournissant une distribution simple et uniforme. Cet algorithme fonctionne bien lorsque tous les serveurs ont une capacité similaire et que toutes les requêtes ont des exigences de ressources similaires.
Le moins de connexions route les requêtes vers les serveurs avec le moins de connexions actives. Cette approche gère mieux les durées de requêtes variables que le round-robin. Les serveurs qui complètent rapidement les requêtes reçoivent naturellement plus de nouvelles requêtes.
La distribution pondérée attribue différentes proportions de trafic à différents serveurs. Vous pourriez envoyer 70 % du trafic vers des serveurs puissants et 30 % vers des serveurs plus petits. Cette flexibilité vous aide à utiliser efficacement une infrastructure hétérogène.
Le hachage IP route les requêtes de la même IP client vers le même serveur. Cette cohérence aide à la gestion des sessions et à la mise en cache. Les utilisateurs obtiennent des expériences cohérentes, et les caches côté serveur deviennent plus efficaces.
Les vérifications de santé garantissent que les équilibreurs de charge ne routent le trafic que vers les serveurs sains. Les équilibreurs testent périodiquement la réactivité de chaque serveur. Les serveurs défaillants sont automatiquement retirés de la rotation jusqu'à ce qu'ils récupèrent.
Gestion des sessions dans l'architecture évolutive
Les applications sans état sont les plus faciles à mettre à l'échelle car n'importe quel serveur peut gérer n'importe quelle requête. Les utilisateurs n'ont pas de données de session liées à des serveurs spécifiques, donc les équilibreurs de charge peuvent router librement en fonction de la capacité actuelle.
Les sessions persistantes routent toutes les requêtes d'un utilisateur vers le même serveur pendant la durée de leur session. Cette approche simplifie la gestion des sessions mais réduit la flexibilité de l'équilibrage de charge et crée des problèmes lorsque les serveurs échouent.
La réplication de session copie les données de session sur tous les serveurs. N'importe quel serveur peut gérer n'importe quelle requête car tous les serveurs ont toutes les données de session. Cette approche offre une bonne résilience mais devient inefficace à mesure que le nombre de serveurs augmente.
Le stockage de session centralisé conserve les données de session dans un cache ou une base de données partagé. Tous les serveurs d'application lisent et écrivent dans ce magasin central. Cette approche évolue bien et gère les défaillances de serveur avec élégance.
L'authentification basée sur des jetons élimine complètement le stockage de session côté serveur. Les clients incluent des jetons d'authentification avec chaque requête. Les serveurs valident les jetons sans maintenir d'état de session. Cette approche sans état évolue sans effort.
Considérations d'infrastructure
Les équilibreurs de charge cloud s'intègrent parfaitement avec les groupes de mise à l'échelle automatique. À mesure que votre application augmente ou diminue, les équilibreurs de charge s'ajustent automatiquement pour router le trafic vers les instances actuelles. Cette automatisation est essentielle pour la mise à l'échelle élastique.
La terminaison SSL au niveau de l'équilibreur de charge décharge le travail de chiffrement des serveurs d'application. L'équilibreur de charge gère la poignée de main SSL coûteuse et déchiffre le trafic avant de le router vers les serveurs backend. Cette optimisation améliore la capacité des serveurs d'application.
L'équilibrage de charge géographique route les utilisateurs vers le centre de données le plus proche. Les utilisateurs en Amérique du Nord se connectent à vos serveurs de Montréal tandis que les utilisateurs européens se connectent aux serveurs européens. Cette distribution réduit la latence et fournit des capacités de reprise après sinistre.
La protection DDoS s'intègre souvent avec l'infrastructure d'équilibrage de charge. Les équilibreurs de charge peuvent détecter et filtrer le trafic malveillant avant qu'il n'atteigne vos serveurs d'application. Cette protection est de plus en plus essentielle pour les applications exposées à Internet.
La surveillance et l'observabilité sont critiques pour les systèmes équilibrés en charge. Vous avez besoin de visibilité sur la distribution du trafic, la santé des serveurs et les temps de réponse. Une bonne surveillance vous aide à identifier les goulots d'étranglement et à optimiser votre configuration.
Pour les entreprises mettant en œuvre une architecture évolutive, l'équilibrage de charge est rarement optionnel. Même les applications modestes bénéficient de la fiabilité et de la flexibilité qu'il offre. La complexité est gérable, surtout avec les plateformes cloud qui offrent l'équilibrage de charge en tant que service géré.
Conclusion
Choisir les bons modèles d'architecture pour votre application nécessite d'équilibrer les besoins actuels avec la croissance future. Il n'existe pas de solution universelle qui fonctionne pour chaque entreprise à chaque étape.
Commencez par évaluer honnêtement vos exigences d'échelle. Une startup validant l'adéquation produit-marché a des besoins différents d'une entreprise établie connaissant une croissance rapide. La sur-ingénierie gaspille des ressources tandis que la sous-ingénierie crée des réécritures douloureuses plus tard.
La plupart des stratégies d'architecture évolutive réussies commencent simplement et évoluent progressivement. Lancez avec un monolithe bien conçu, ajoutez de la mise en cache et de l'équilibrage de charge à mesure que le trafic augmente, puis envisagez les microservices ou les modèles événementiels lorsque la complexité et l'échelle l'exigent.
Les modèles couverts dans cet article fonctionnent ensemble plutôt qu'en concurrence. Les systèmes du monde réel combinent souvent l'architecture en couches avec la communication événementielle, les microservices avec des bases de données monolithiques, et la mise en cache à plusieurs niveaux. Comprendre les forces de chaque modèle vous aide à composer la bonne solution.
Faites attention à vos goulots d'étranglement. Surveillez les performances en continu pour comprendre où votre système rencontre des difficultés. Mettez à l'échelle ces domaines spécifiques plutôt que d'optimiser prématurément tout. Cette approche ciblée maximise le retour sur vos investissements architecturaux.
Passer à l'étape suivante
Les équipes de développement professionnelles apportent une expérience dans la mise en œuvre de ces modèles à travers divers projets. Elles ont vu ce qui fonctionne, ce qui échoue, et comment adapter les modèles à des contextes commerciaux spécifiques.
Chez Vohrtech, nous aidons les entreprises montréalaises et au-delà à concevoir et mettre en œuvre une architecture évolutive appropriée à leur stade et à leurs objectifs. Que vous partiez de zéro ou que vous fassiez évoluer des systèmes existants, nous nous concentrons sur la fourniture de valeur sans complexité inutile.
La bonne architecture soutient la croissance de votre entreprise plutôt que de la contraindre. Elle offre de la place pour évoluer à mesure que vous en apprenez davantage sur vos utilisateurs et votre marché. Plus important encore, elle offre des performances fiables qui maintiennent les utilisateurs satisfaits et votre entreprise fonctionnant en douceur.
Si vous évaluez l'architecture de votre application ou planifiez un nouveau projet, nous serions ravis de discuter de vos besoins spécifiques. Contactez-nous pour explorer comment nous pouvons vous aider à construire des systèmes qui grandissent avec votre succès.